StrataSearch is a documentation search engine that uses an Advanced RAG (Retrieval-Augmented Generation) pipeline to understand code evolution. It automatically distinguishes between deprecated patterns and modern best practices in its responses, making it ideal for navigating legacy and modern codebases.
The system implements a multi-stage RAG pipeline designed for high-precision technical retrieval, runs entirely offline with local models, and provides a command-line-driven workflow for easy data management.
- Legacy vs Modern Code Analysis: Automatically identifies deprecated code patterns and suggests modern alternatives.
- Advanced RAG Pipeline: Implements a multi-stage retrieval process including multi-query generation and cross-encoder re-ranking for high-precision results.
- Command-Line Driven Workflow: Includes Django management commands for data scraping, knowledge base ingestion, and RAG pipeline evaluation.
- Private & Local-First: Runs entirely offline using local models with Ollama, ensuring data privacy and control.
Screenshots
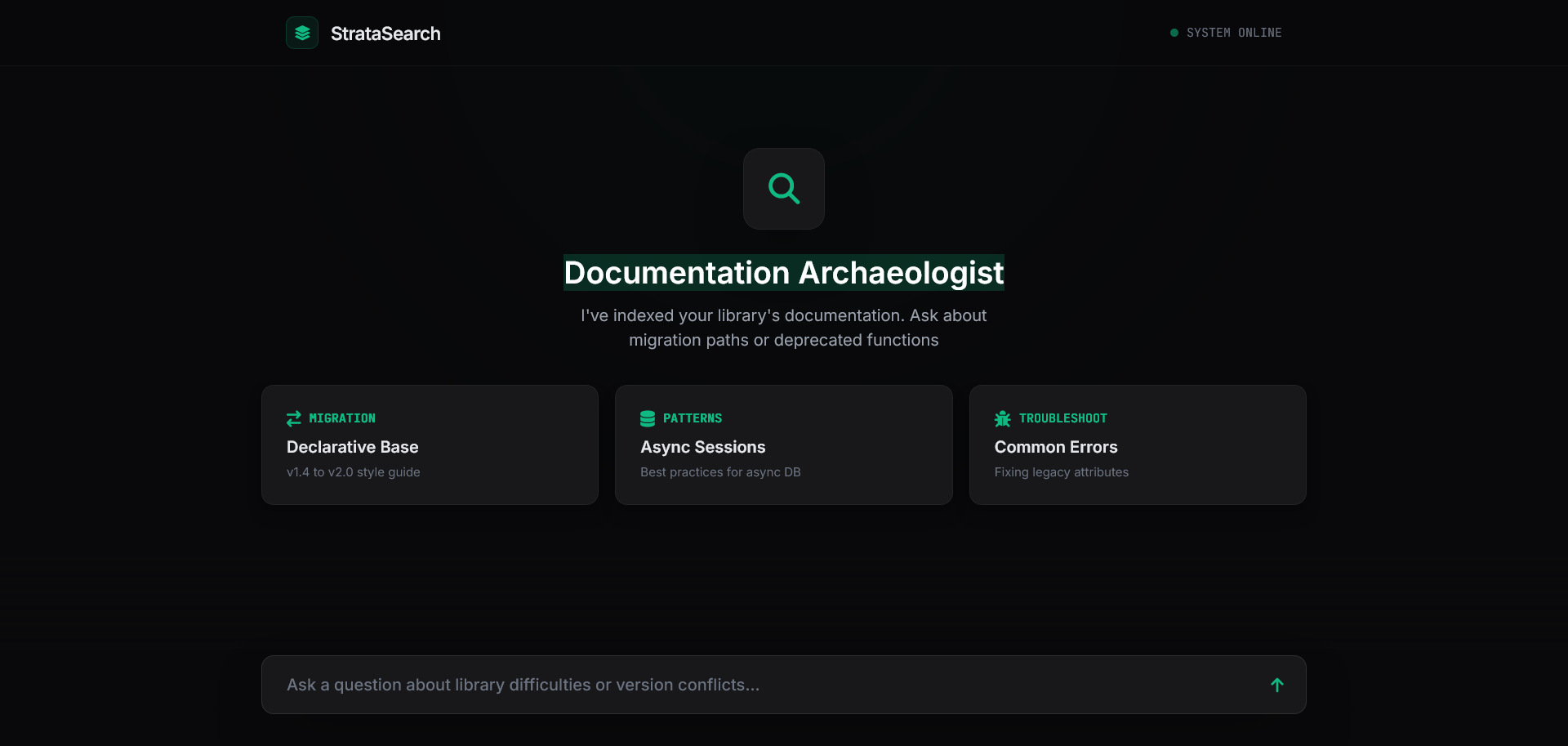
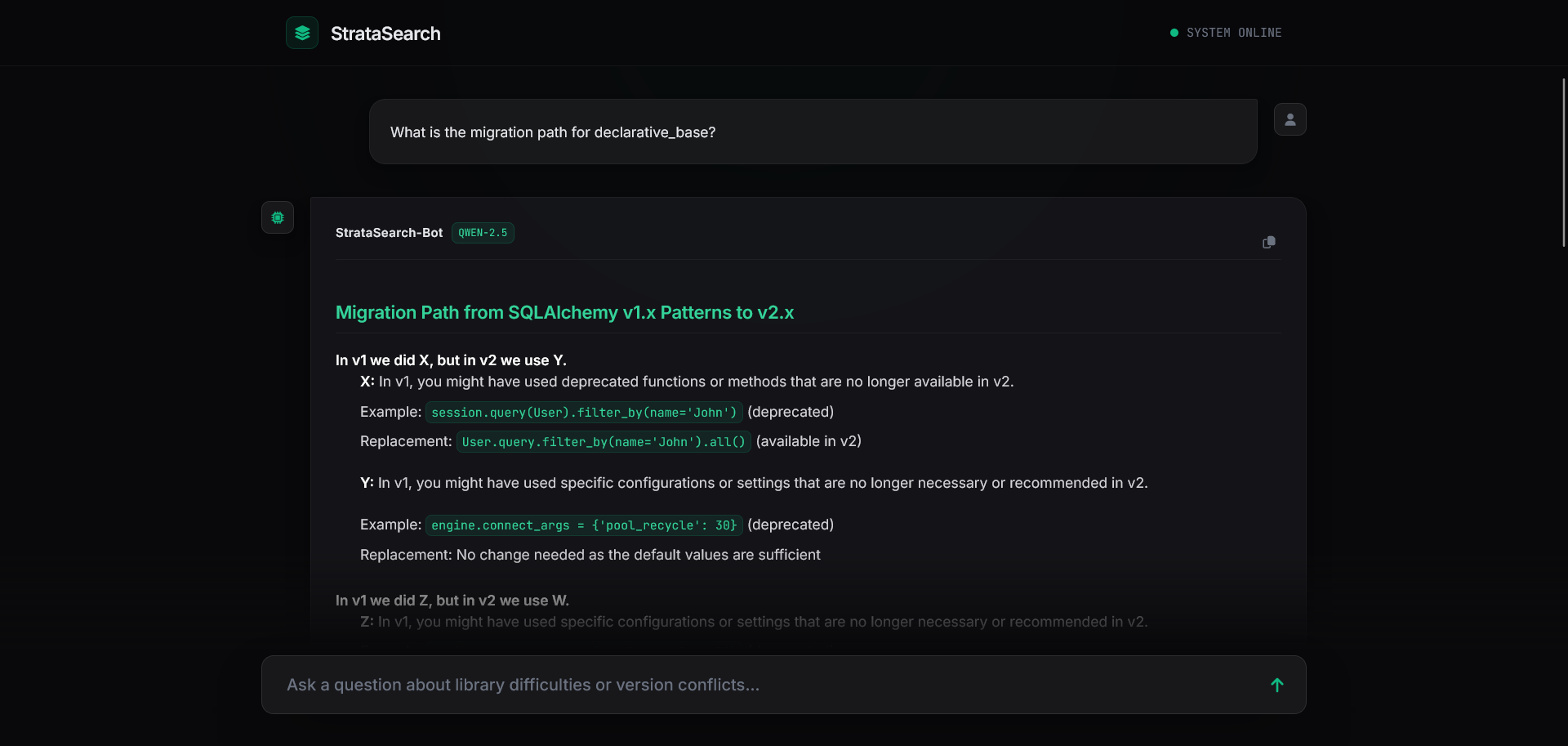
Getting Started
Prerequisites
- Python 3.10+
- Ollama running locally
1. Setup & Installation
git clone https://github.com/joshuaglaz/stratasearch.git
cd stratasearch
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
pip install -r requirements.txt2. Build Knowledge Base
First, scrape the documentation you want to index.
python manage.py scrape https://docs.sqlalchemy.org/en/20/ --depth 2 --max 20Then, ingest and index the scraped data.
python manage.py ingest3. Run the Server
python manage.py runserverTech Stack
| Component | Technology | Description |
|---|---|---|
| Backend | Django 5.0 | Async Views & Management Commands |
| Pipeline | LangChain | RAG Orchestration |
| Inference | Ollama | Local LLM (Qwen 2.5) |
| Search | FAISS + FlashRank | Vector Search + Cross-Encoder Re-ranking |
| Frontend | HTMX + Tailwind | Reactive UI without heavy frameworks |