content-sim is a hybrid PHP/Python application that aggregates posts and tweets, computes keyword‑proximity scores, and surfaces the most contextually relevant results. It handles session management across multiple Instagram and Twitter accounts, supports headless scraping, and offers a web interface for interactive searches.
- Social media scraping: Fetches content from Instagram, Twitter, and YouTube.
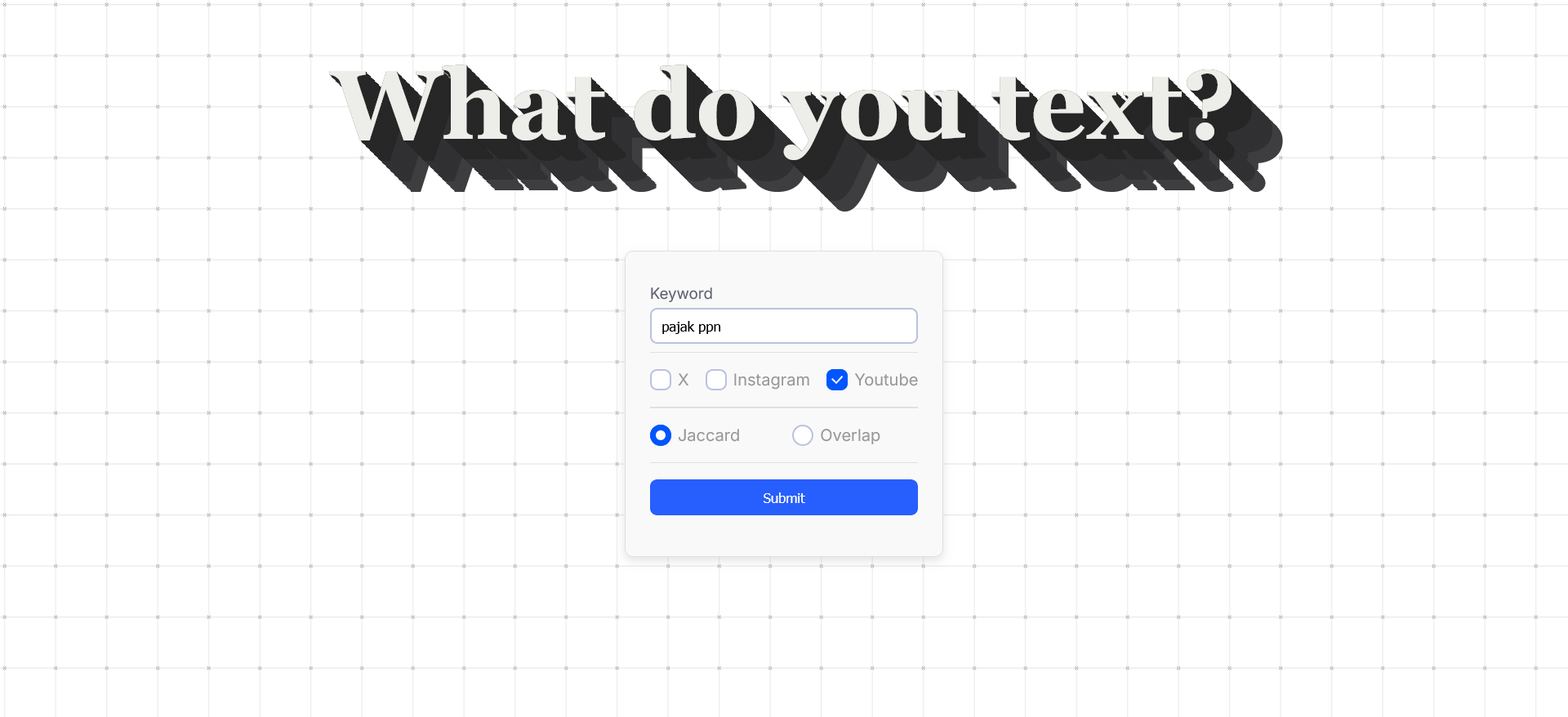
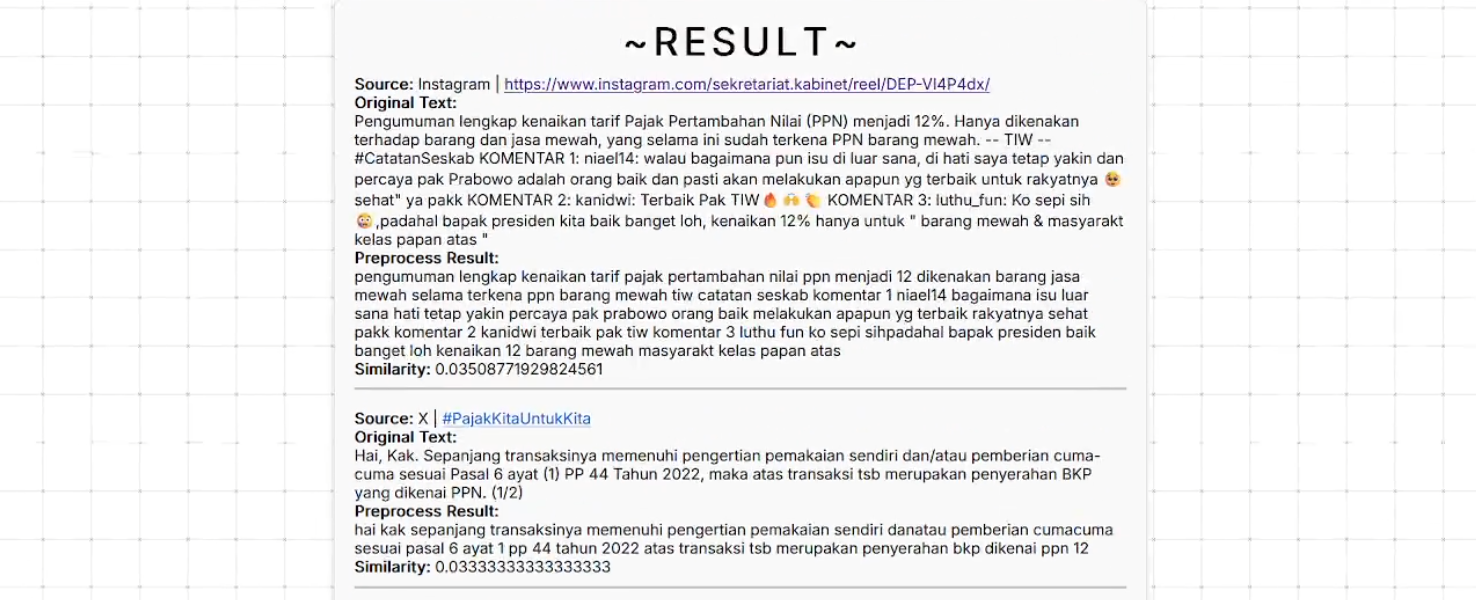
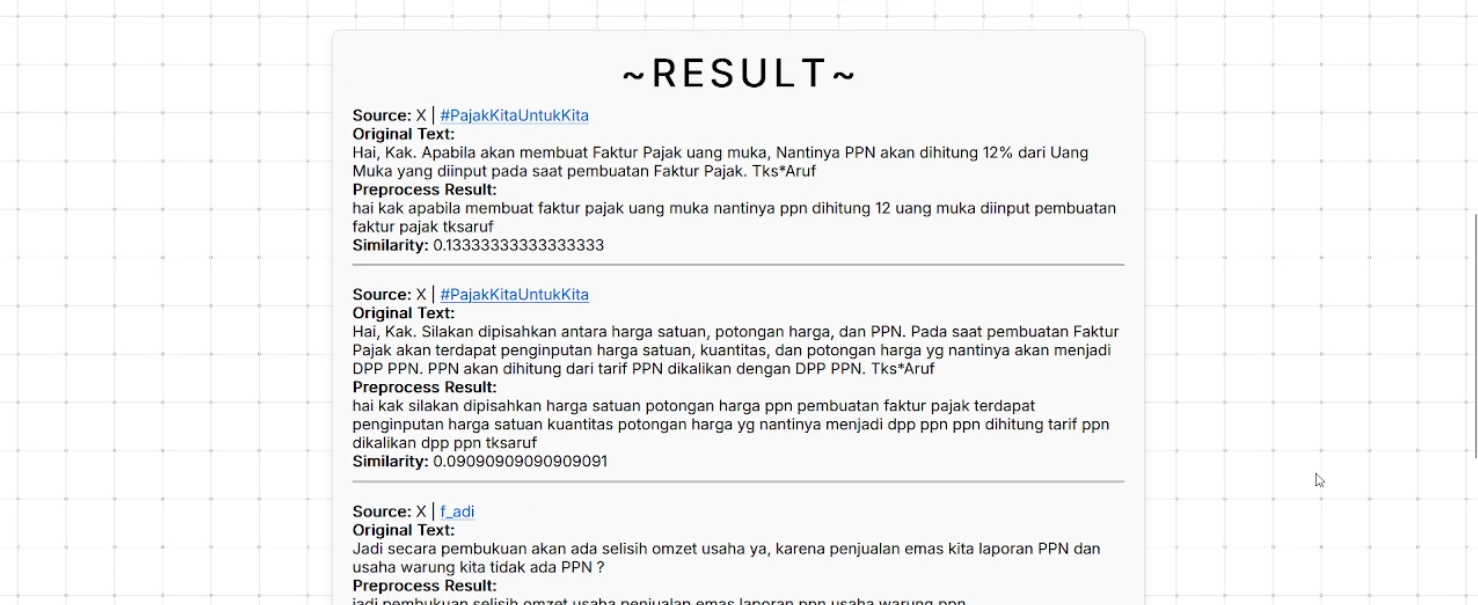
- Keyword-Proximity Ranking: Ranks posts by closeness to user‑specified.
- Session Management: Rotates authenticated cookies for large‑scale scrapes.
- Web-based interface: Easy to use and accessible from any browser.
- Customizable queries: Tailor your searches for specific needs.
Tech Stack
- Backend: Python (Flask)
- ML Libraries: TensorFlow, Keras, Librosa
- Client: Android (Java/Kotlin)
- Other Tools: NumPy, Pandas, GitHub Actions for CI/CD
Screenshots
Installation
git clone https://github.com/JoshuaGlaZ/content-similarity.git
cd content-similarity
# PHP Server Setup
composer install # if you use Composer for dependencies
# or ensure PHP v8+ is installed, start built‑in server:
php -S localhost:8080 -t public/
# Python Scraper Setup
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txtUsage
- Start web server (php -S localhost:8080 -t public/).
- Launch desired scrapers (twitter_scrapper.py, ws-ig.py, youtube.py) with your credentials.
python twitter_scrapper.py
python ws-ig.py
python youtube.py- Navigate to http://localhost:8080/ and enter search keywords to view results.